我组四篇论文被 INTERSPEECH 2025 录用
======
近日,我课题组共有 四篇论文 被国际语音大会 INTERSPEECH 2025 录用。四项工作分别面向多通道主动降噪(MCANC)、无线声传感器网络(WASNs)语音增强、HRTF 插值、语音活动检测与重叠语音检测(VAD/OSD)等关键声学任务,展示了我组在 智能声学与语音信号处理 方向的系统性研究进展。
1. Reference Subset Selection Considering Filter Length for Multi-channel Active Noise Control
作者: 呼德(通讯作者)、刘姝瑶、何艳榕
在多通道有源噪声控制系统中,更多的参考麦克风可带来更强的降噪能力,但也意味着更高的计算代价。本文提出一种 同时选择参考麦克风子集与自适应确定滤波器阶数 的优化方法:
- 稀疏性驱动的麦克风选择:利用稀疏正则项自动筛选关键参考通道;
- 辅助向量促进高阶系数收敛为零:实现最优滤波器阶数自适应确定;
- 重加权策略:进一步提升稀疏性,减少计算复杂度;
- 保持降噪性能的同时显著降低计算负担,提升实时性。
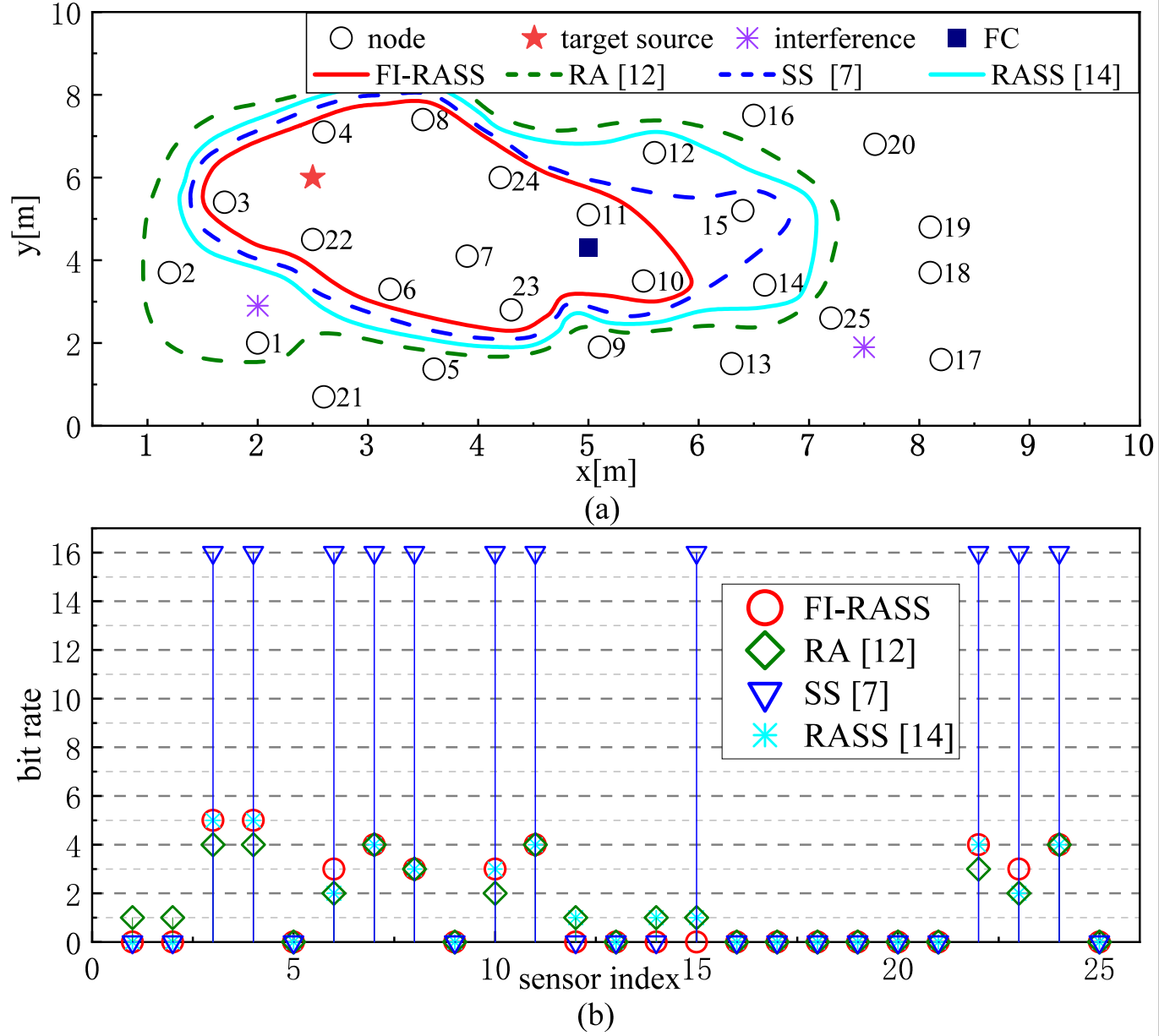
2. Joint Rate Allocation and Sensor Selection for Speech Enhancement in Wireless Acoustic Sensor Networks
作者: 呼德(通讯作者)、李琪龙
在能量受限的无线声学传感器网络中,高能效语音增强是核心挑战。本文提出一种 频率不变的比特率分配 + 传感器选择联合优化(FI-RASS)方法:
- 在比特分配中引入稀疏性,避免 NP 难的布尔规划;
- 跨频率一致的传感器选择策略,解决传统 RASS 频率间选择不一致的问题;
- 重加权稀疏优化,进一步降低网络整体能耗;
- 在保证语音增强质量的前提下显著提高能效。
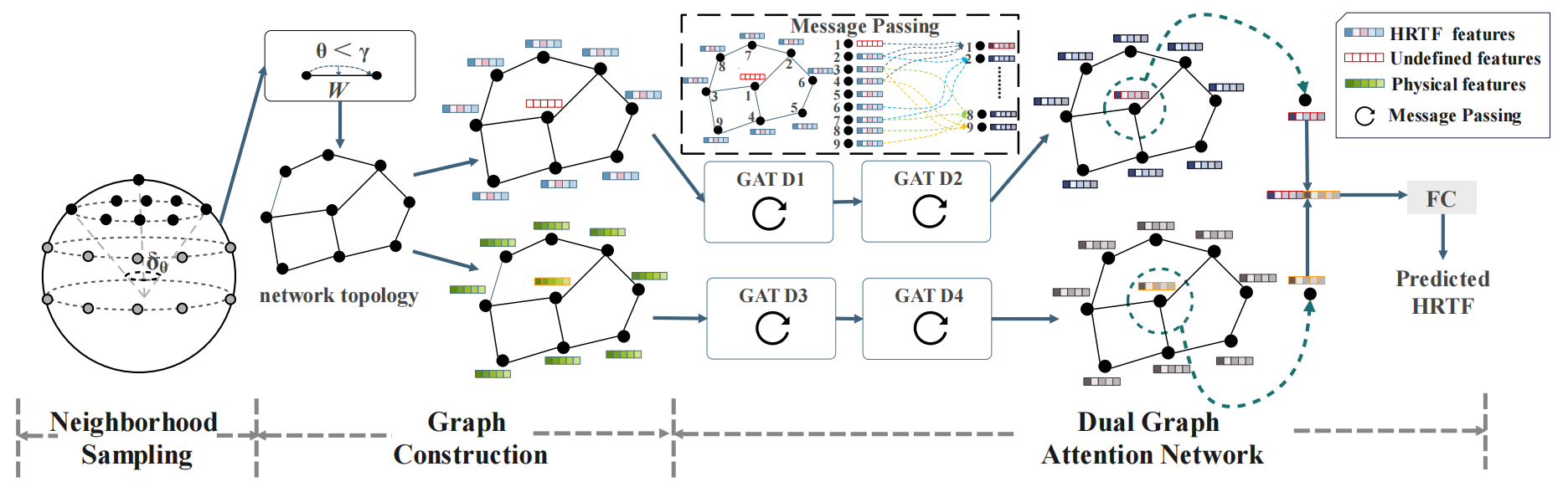
3. D-GAT: Dual Graph Attention Network for Global HRTF Interpolation
作者: 胡俊升、李少杰、斯琴图雅、呼德(通讯作者)
HRTF(头相关传递函数)在 VR/AR 空间音频中至关重要,但其高密度采样成本昂贵。本文提出一种 双图注意力网络 D-GAT,从空间域与频率域联合建模 HRTF 的结构特性:
- 空间图(位置维度)+ 频率图(频带维度)双图结构;
- 双注意力融合机制:在两张图之间共享与交互关键特征;
- 全局插值能力更强,可在稀疏测量情况下恢复完整 HRTF;
- 在多个公开数据集上,优于传统插值和单图神经网络方法。
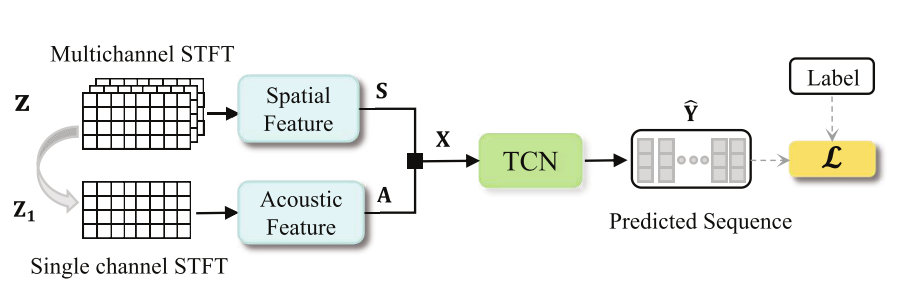
4. Temporal Convolutional Network with Smoothed and Weighted Losses for Distant VAD and Overlapped Speech Detection
作者: 李少杰、斯琴图雅、呼德(通讯作者)
远讲语音场景中,由于混响、噪声与说话人重叠,VAD/OSD 任务变得极具挑战。本文提出基于 TCN(Temporal Convolutional Network)的改进框架:
- 利用 TCN 建模长时依赖,提升远讲场景中的建模能力;
- 平滑损失函数 有效减少输出的突变,提高语音片段边界一致性;
- 加权损失策略 强化模型对重叠语音与弱语音的检测能力;
- 在多种真实远讲场景下均取得显著优于基线的性能。
四篇论文的录用充分展示了我组在 空间音频、主动降噪、语音增强、语音前端处理 等方向的持续探索与创新。未来,我们将继续面向智能声学的核心问题深入研究,推动相关技术在实际系统中的应用。